
Imitation Learning explained
Here is my attempt to explain the notions and intuitions behind Imitation Learning with the best of my knowledge. Credits to this very nice blog where I have learned most of the things that I have understood about the concept, and to this website for the image above. Now let’s directly dive in.
1. Brief intuitions

The field of Reinforcement Learning is an area of machine learning where an intelligent agent interacts with an environment in order to learn a policy (i.e. a set of rules) that maximizes the rewards given by the environment. More details can be found on the course notes that I have took on the Reinforcement Learning class that I am currently following.
1.1 How to find the best policy in RL?
There are several algorithms and learning methods in order to learn the best policy in RL. I will not explain in detail all the possible ways to learn the best policy in RL, but the tricky part there is to design the reward function. In the typical and basic scenario, the reward function are designed manually due to the simplicity of the problem (e.g. a simple Atari game).
1.2 Why Imitation Learning?
This can be extremely complex in some scenarios (e.g. self-driving cars) where the environment can get extremely complex, thus the reward function really hard to design manually. Here comes Imitation Learning (IL) to solve this issue. I am quoting below a very clear explanation of IL from the blog I am referring.
It is now very obvious why Imitation Learning is called so. An agent learns by imitating an expert that shows the correct behavior on the environment.
1.3 Different types of algorithms
Several types of algorithms exists for IL from the simplest to the less simple: Behavioural Cloning, Direct Policy Learning via Interactive Demonstrator and Inverse Reinforcement Learning. Let’s quickly focus on the Behavioural Cloning that works as follows:
- The agent collects the demonstrations (trajectories) from the expert
- Treat the demonstrations as i.i.d state-action pairs
- Learn the optimal policy using supervised learning
In practice, this algorithm is not that robust. This is due to the fact that the state-actions paris are treated as i.i.d (every pair is independent from each other).
2. Imitation learning in practice
Let us consider that we are evolving in an environment where we get a reward at each state and we have a predefined finite set of actions. Let us also assume that it is really hard to design an accurate reward function due to the various possibility of sets.
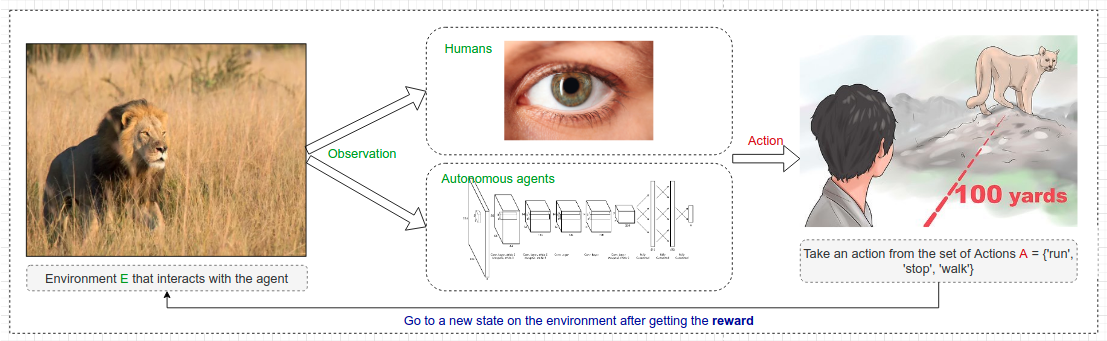
2.1 Behavioural Cloning
As described in this example above (Original content), the reward function is really hard to design manually as the environment is extremely stochastic, i.e. the lion’s behavior is really unpredictable.
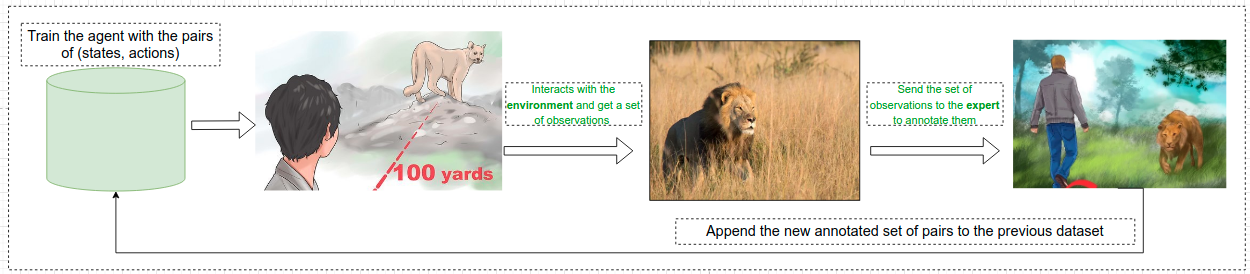
To tackle this issue, the IL aims at collecting a training data from an expert beforehand. In our scenario, we can imagine that a lion expert will demonstrate how to deal with the environment and we will collect all the records of the scenarios that happened to build a training dataset.

After getting the training data, we can learn an optimal policy by doing supervised learning on the obtain pairs of states and actions.
This typical scenario is called Behavioural Cloning as explained before. But this has some limitations:
- The collected training data is considered to be a set of i.i.d samples (each state is independent between each other). Which is in practice, not the case.
- What if the agent follows a set of paths that the expert did not encountered? This can easily lead to exploring unknown states, and to lead to catastrophic failures
2.2 Towards more accurate training data
What if we can access to our expert’s feedbacks in real time while training our model? That is the main idea behind Direct Policy Learning via Interactive Demonstrator. Let us assume we already have in our bag the training data collected from our lion’s expert.
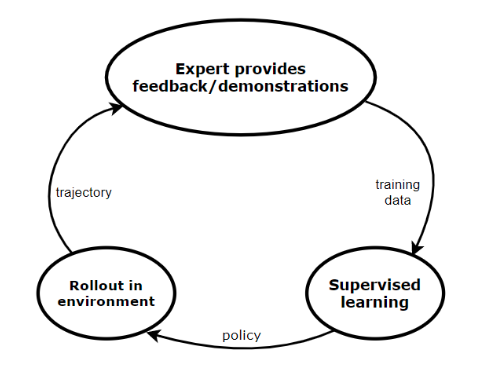
Basilcally from the initial training data:
- We train our agent on it in order to get the first optimal policy
- We run the policy on the environement in order to get the new observations
- Ask our expert to label the new observations (feedbacks)
- Combine both datasets and repeat the steps 1-4 until convergence
By applying this technique, the agent will not suffer from the issues faced with Behavioural Cloning. But this has a price, it is really hard to have a real-time feedback from an expert (a human) while training the model. Also in some cases the concept of expert can be hard to define.