An approach for fitness exercise scoring using Deep Learning
Introduction
Imagine a world where (almost) everything is powered by Artificial Intelligence. Today, some signs of an Artifical Intelligence-guided society are coming into existence. Autonomous cars can automately drive you from a point A to a point B, and more recently, Tesla has revealed the Tesla Bot, the humanoid robot that will be able to help humans for simple tasks.
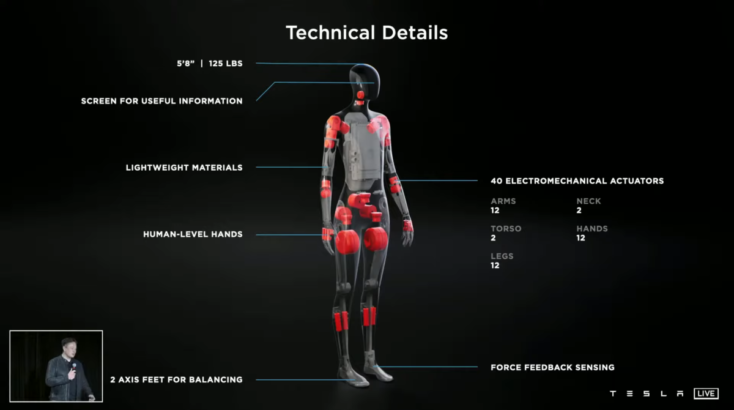
Apart from having society full of AI-powered robots, back in 2019 when we have starting the project together with my teammates and the laboratory ISIR from Sobonne University, we just wanted to try to tackle to problematic of having an AI-based gym trainer for fitness exercises.
Fitness exercises and AI?
Fitness exercises consists mostly of repeated movements that needs to be executed in the most accurate way possible to solicit some specific joints and muscles of our body. If an AI learns how a specific exercise needs to be done correclty, given an execution of this exercise the AI should be able to interpret how far this execution it is from the learned execution. The problem seems exetremly straightforward to forumulate but very hard to translate it into a Machine Learning problem.
Challenges
What is going to be the input data?
If deployed into a real-world application, the input data would clearly be a video. As stated in the previous section, the AI needs to learn how to perform a right execution, which consists of a video of a movement. Does the AI needs to be end-to-end? (Directly from the video to the score). Not that easy.
Given the lack (or the inexistence) of a labeled data for this task, the problematic became very challenging but exciting. We had to create a custom dataset by involving staff members from the lab and hard work since we had to label each frame from each video.
The project’s main problematic has rapidly became Can we create an AI that classifies and scores a fitness movement? to Is Deep Learning well adapted to score a movement?
Transforming the input into another space
Having a model that learns everything end-to-end directly from the video is extremely computationnaly expensive and not robust in practice. It can easily overfit into the persons we have used to train the model or overfit to some contextual information we do not have control on (e.g. the background, the lighting of the room in the videos, etc.). Thus, the input data absolulety needs to be transformed in order to make them more understandable for the Deep Learning model to process it, and to avoid our common ennemy: overfitting.
Long live human poses! What if we express each frame into only the joints of the person in the video? By doing this, we drastically reduce the amount of data (each frame can be expressed using only 30 data points instead of 3x256 pixels!). Back in 2019, OpenPose was the state-of-the-art method for 2D human pose estimation model.

This approach to tackle the problem seemed perfect to us. OpenPose was state-of-the-art, time-consistent (consistent results between each frame) and extremly robust since it has been trained on a very large dataset with a wide variety of different people, background images, lighting conditions, etc. In addition, the outputed keypoints can be normalized and the score would be independent to the size of the human, which in practice is the case.
Deal with different numbers of frames
Each frame is now expressed into a vector of size 30. A video is a concatenation of frames, thus can be expressed with a concatenation of generated vectors. How to deal with inconsitent number of frames accross each video? By just applying a fixed zero-padding on those tensors. Let’s assume the maximum number of frames accross all videos is N. Then each video would have a size (30xN) and the irregular videos will be zero-padded.
Implementations
After manually labelling the data and transforming each video into a (30xN) dimensional tensor we have tried several approaches to output a score given the tensors.
Each 30-dimensional vector is concatenated in the horizontal direction. Arranging the data like the following is similar to having a sequential data where each column corresponds to a specific timestep.
Score predictor as a 1D-CNN
The 1-dimensional filter can learn the linear correlation between each joint at each time step.
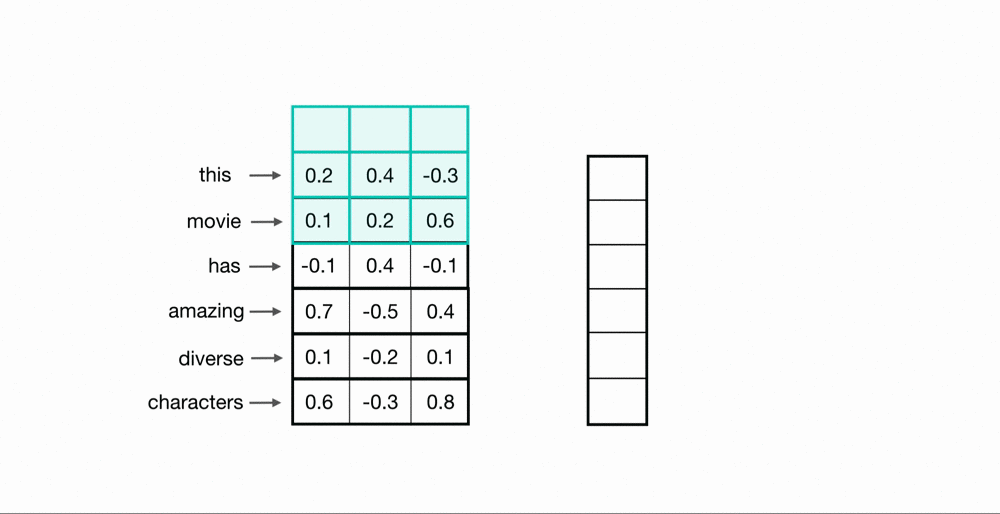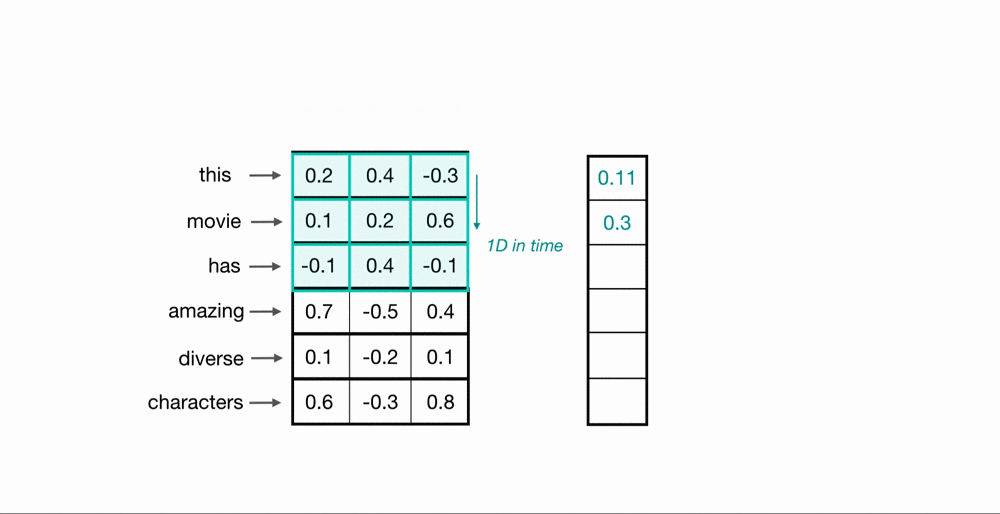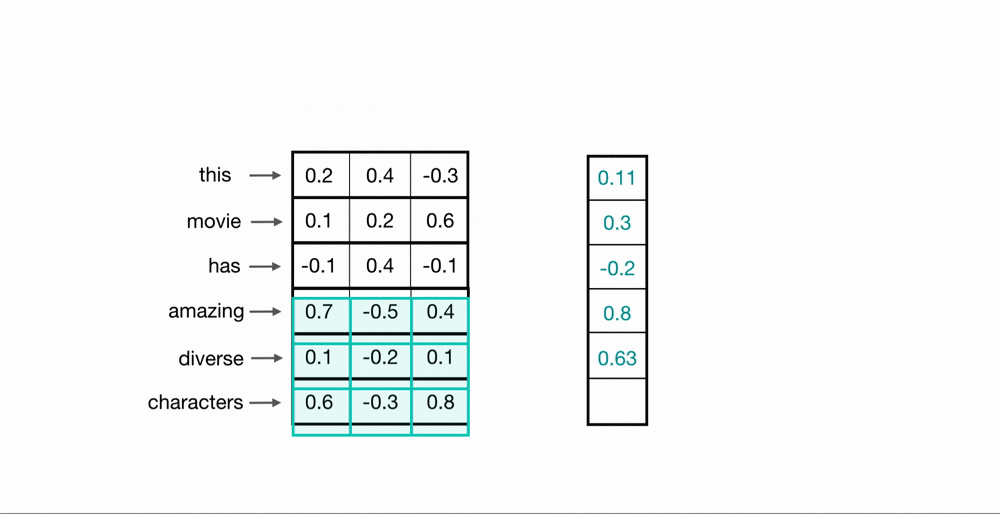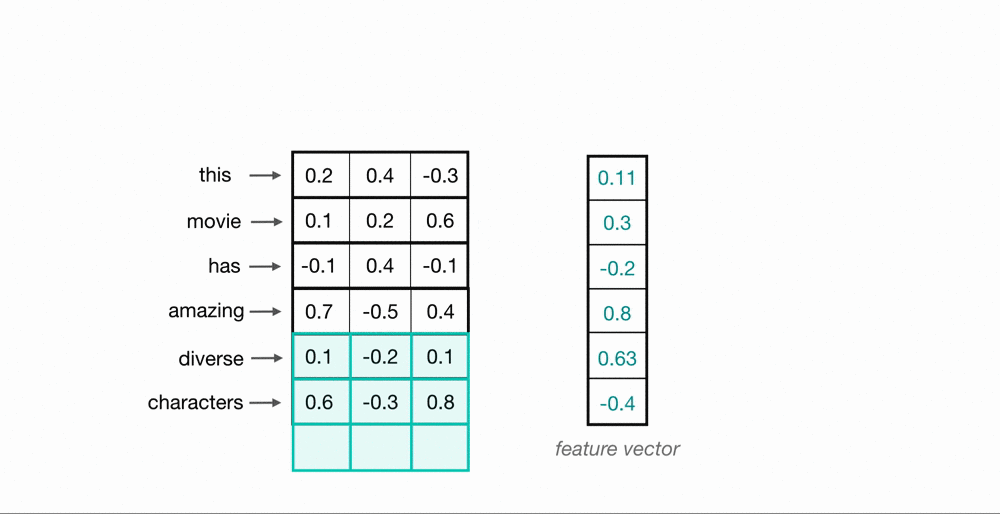
Score predictor as a simple LSTM model
It is a common practice in the Deep Learning litterature to use a LSTM model when dealing with sequential data.
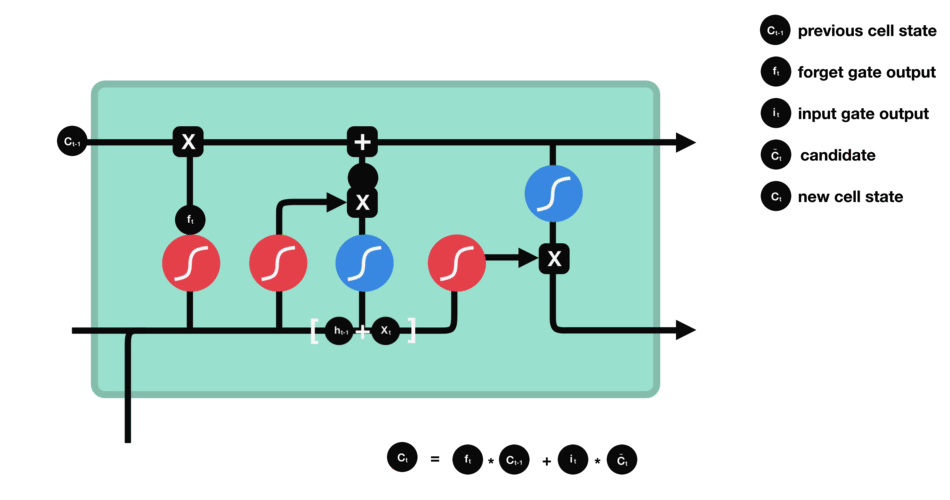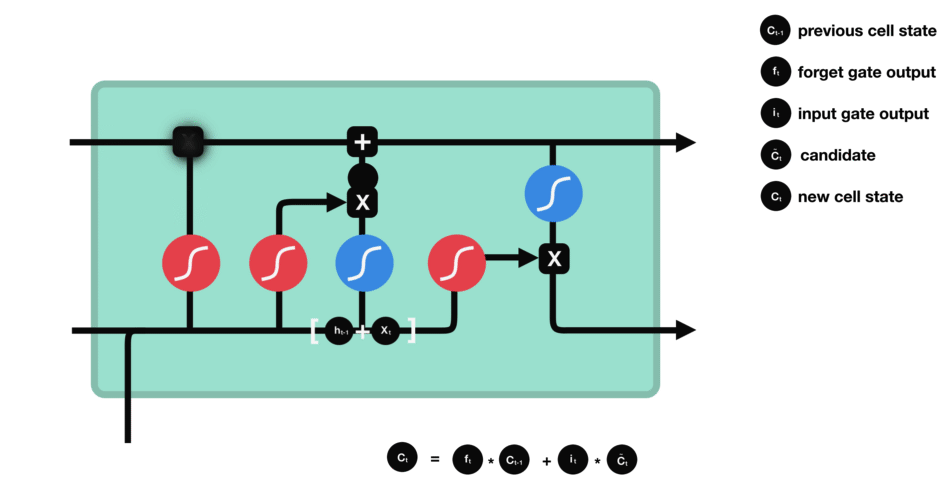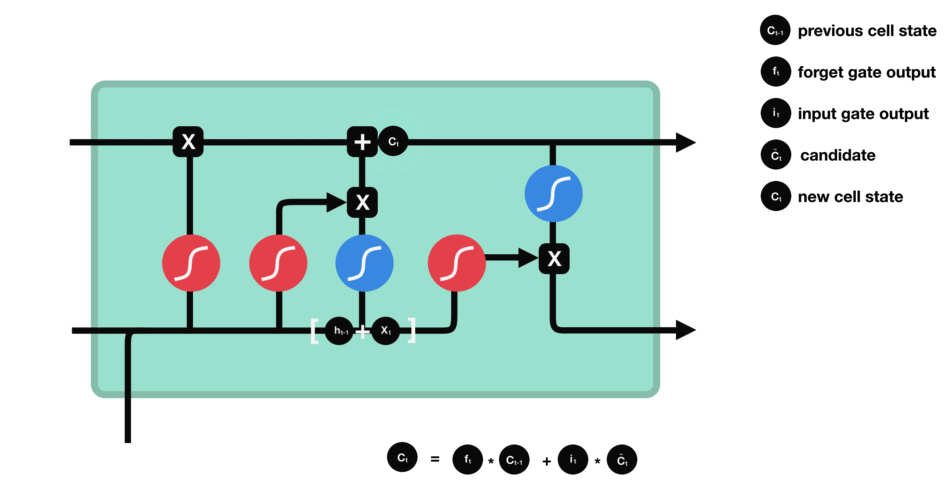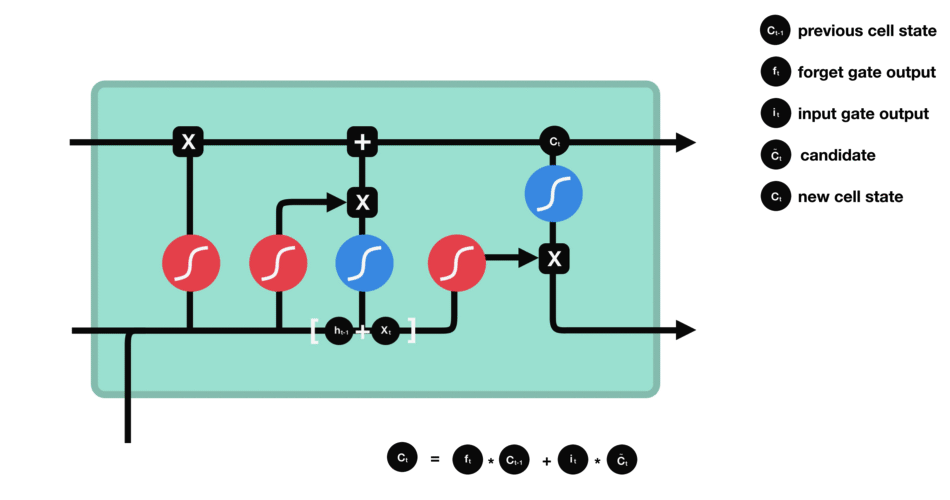
Conclusion
- Trying to have an end-to-end AI is extremely difficult if we want to deploy a robust AI. Breaking down the problem into smaller problems can help and must be considerd.