An unsupervised method for table structure recognition
Problem statement
Some organizations still use huge amounts of scanned tables / invoices. Rather than manually typing the contents of the tables into an excel file, one can think of using Deep Learning to tackle this problem. Once you identify the distinguishable cells on the tables, we can pass an OCR (Optical Character Recognition) to each cell to read its contents and convert it to an excel file for example.

Here comes the task of table structure recognition, the main goal would be to efficiently detect the individual cells given an image containing textual information (characters, digits).
This work has been achieved through one of my internships together with Arthur Zucker, and the work resulted on the publication of a research article that can be browsed here.
Why this task is so challenging ?
This task can be tackled from several directions, if we assume that the tables are always perfect and clean, a simple computer vision approach (line / edge / corner detections algorithms) would be sufficient. However, the tables that have been given by our clients are hard to process and doesn’t follow the same pattern in terms of global structure.
In this case, Deep Learning is the best fit to tackle this problem. But How ? For example, we can think of an object detection algorithm that predicts the cell regions or the ruling lines of the input table. But getting a labeled dataset for this task makes thing very complicated, and even if we had access to such dataset, there is no guarantee that the model will perform well in practice. What if the table contains unseen characters from a different alphabet, etc.
Here comes the well-discussed border that lies between the research field and industry. In research most of the benchmark datasets are clean and sometimes, ML models trained and evaluated on some specific datasets are hard to deploy in real-world application.
Fortunately, there is a high excitement around text detection algorithms using Deep Learning in the litterature and we can take advantage of it. When we were working at this project, CRAFT algorithm was the state-of-the-art text detection algorithm.
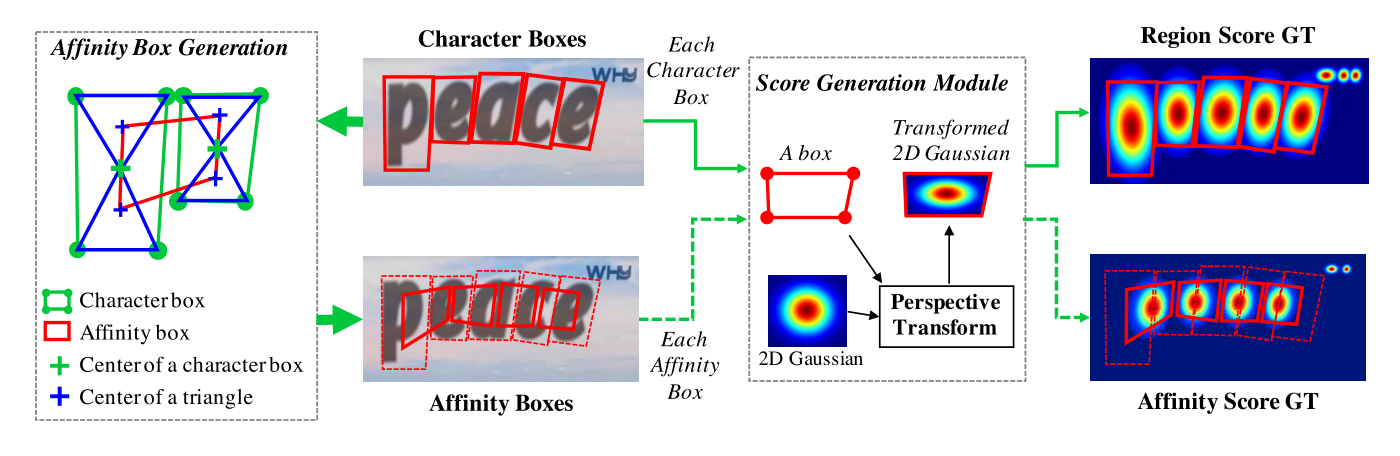
Since these models are state-of-the-art models we maximize the chances that at test time, it will handle well the corner cases. In practice, this model worked well on scanned invoices so we have decided to stick with it. As stated before, CRAFT was the state-of-the-art at the time we were working on the project, this method can be implmented using current state-of-the-art models.
What is next ?
The idea of the paper is to deploy a hierarchical AI-based solution for that. If you are curious about the method and know more about it, please visit this website and request for a full version of the paper.